Figure.1
| PolarSPARC |
Quick Primer on LangChain
| Bhaskar S | *UPDATED*11/09/2025 |
Overview
LangChain is a popular, open-source, agentic orchestration framework that provides a standardized abstraction for developing agentic AI applications by hiding the complexities of working with the different Large Language models (or LLMs for short).
LangChain provides a collection of core component abstractions (or modular building blocks) that could be linked or "Chained" together to create complex agentic workflows (or AI applications) to solve a plethora of tasks.
The following are the list of some of the important component modules from LangChain:
Models :: are standardized abstractions for interacting with AI models and are primarily of three types:
LLM Models are designed for interacting with the various LLMs, which take text input and generate text output
Chat Models are designed for interacting with the various LLMs using a chat style interaction in which the previous chat input is used as the context
Embedding Models are designed to convert an input text to a numerical embedding vector
Agents :: utilize models as a reasoning or decisioning engine to determine the next set of action(s) to take (including invoking specified tools) to achieve a specific end goal
Messages :: are the fundamental abstractions of context for the models. They represent the input to and the output from the models and encapsulate the content and metadata. There are four types of standardized message abstractions:
System Message provides a context for the chat conversation and influences the model behavior
Human Message represents the user input for interactions with the model
AI Message represents the response from the model
Tool Message represents the response from a tool invocation by the model
Memory :: are used for preserving user prompts and responses from the LLMs so that they can be used for providing the context for future interactions with the LLMs
Retrieval :: are related to how one can pass large amounts of user specific contextual data along with the instruction prompt to the LLMs. There are four types of standardized retrieval abstractions:
Document Loaders are useful for loading data documents from different sources, such as files (.txt, .pdf, .mp4, etc), from the web, or any other available sources.
Text Splitters are useful for splitting long documents into smaller semantically meaningful chunks so that they can be within the limits of the LLMs context window size
Vector Stores are used for storing vector embeddings of user specific documents and for later retrieval of similar documents
Retrievers are generic interfaces which are useful for querying embedded documents from various vectors sources including Vector Stores
Middleware :: is a component that allows one to customize the behavior of an agent through various interception points
The intent of this article is NOT to be exhaustive, but a primer to get started quickly.
Installation and Setup
The installation and setup will be on a Ubuntu 24.04 LTS based Linux desktop. Ensure that Ollama is installed and setup on the desktop (see instructions).
In addition, ensure that the Python 3.1x programming language as well as the Jupyter Notebook package is installed and setup on the desktop.
Assuming that the ip address on the Linux desktop is 192.168.1.25, start the Ollama platform by executing the following command in the terminal window:
$ docker run --rm --name ollama -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.12.9
If the linux desktop has Nvidia GPU with decent amount of VRAM (at least 16 GB) and has been enabled for use with docker (see instructions), then execute the following command instead to start Ollama:
$ docker run --rm --name ollama --gpus=all -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.12.9
For the LLM models, we will be using the Microsoft Phi-4 Mini for the chat interactions and the IBM Granite 4 Micro model for the tools execution.
Open a new terminal window and execute the following docker command to download the IBM Granite 4 Micro model:
$ docker exec -it ollama ollama run granite4:micro
After the model download, to exit the user input, execute the following user prompt:
>>> /bye
Next, in the opened terminal window and execute the following docker command to download the Microsoft Phi-4 Mini model:
$ docker exec -it ollama ollama run phi4-mini
After the model download, to exit the user input, execute the following user prompt:
>>> /bye
Next, to install the necessary Python modules for this primer, execute the following command in the opened terminal window:
$ pip install chromadb dotenv langchain langchain-chroma langchain-core langchain-community langchain-ollama
This completes all the installation and setup for the LangChain hands-on demonstrations.
Hands-on with LangChain
Create a file called .env with the following environment variables defined:
LLM_TEMPERATURE=0.2 OLLAMA_CHAT_MODEL='phi4-mini:latest' OLLAMA_TOOLS_MODEL='granite4:micro' OLLAMA_BASE_URL='http://192.168.1.25:11434' CHROMA_DB_DIR='/home/polarsparc/.chromadb' BOOKS_DATASET='./data/leadership_books.csv' MPG_SQLITE_URL='sqlite:///./data/auto_mpg.db'
To load the environment variables and assign them to Python variable, execute the following code snippet:
from dotenv import load_dotenv, find_dotenv
import os
load_dotenv(find_dotenv())
llm_temperature = float(config.get('LLM_TEMPERATURE'))
ollama_chat_model = config.get('OLLAMA_CHAT_MODEL')
ollama_tools_model = config.get('OLLAMA_TOOLS_MODEL')
ollama_base_url = config.get('OLLAMA_BASE_URL')
chroma_db_dir = config.get('CHROMA_DB_DIR')
books_dataset = config.get('BOOKS_DATASET')
mpg_sqlite_url = config.get('MPG_SQLITE_URL')
To initialize a client instance of Ollama running the desired LLM model phi4-mini:latest, execute the following code snippet:
from langchain.chat_models import init_chat_model
ollama_chat_llm = init_chat_model('ollama:'+ollama_chat_model, base_url=ollama_base_url, temperature=llm_temperature)
Notice the use of the model provider prefix 'ollama:' along with the model name. This prefix loads and initializes the desired model provider (Ollama in this case).
The temperature parameter in the above code is a value that is between 0.0 and 1.0. It determines whether the output from the LLM model should be more "creative" or be more "predictive". A higher value means more "creative" and a lower value means more "predictive".
To initialize an instance of a HumanMessage and a SystemMessage, execute the following code snippet:
from langchain_core.messages import HumanMessage, SystemMessage human_msg = HumanMessage(content='What is the current time in London if the current time in New York is 9 pm EST?') system_msg = SystemMessage(content='You are a helpful assistant.')
To send the just creates messages as input to the Ollama chat model, execute the following code snippet:
messages = [system_msg, human_msg] result = ollama_chat_llm.invoke(messages) result.pretty_print()
Executing the above Python code generates the following typical output:
================================== Ai Message ================================== To determine what time it currently is in London when it's 9 PM Eastern Standard Time (EST) in New York, we need to consider that London's standard time zone during daylight saving times is British Summer Time (BST), which is typically UTC+1. During the winter months or if Daylight Saving has ended for a particular year and region, it would be Greenwich Mean Time (GMT), which is usually UTC. Assuming it's currently summer in both New York and London: - 9 PM EST corresponds to approximately 11:00 PM BST/UTC on August 1st. If we are not considering Daylight Saving time adjustments or if the question refers specifically during winter months when DST might be different, we'd need additional information about whether British Summer Time is currently in effect. Without this specific context for daylight saving times (DST), a general answer would still place London at approximately 11:00 PM BST/UTC.
Instead of creating and using a HumanMessage and a SystemMessage, one can achieve the same result using a regular Python dictionary as shown in the following code snippet:
result = ollama_chat_llm.invoke([
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'What is the current time in Tokyo if the current time in New York is 9 pm EST?'}
])
result.pretty_print()
Executing the above Python code generates the following typical output:
================================== Ai Message ================================== To determine the current time in Tokyo when it's 9 PM Eastern Standard Time (EST) in New York, we need to consider that Japan typically observes Japanese Standard Time (JST), which does not change with daylight saving times. JST is usually UTC+9 hours. New York operates on either Eastern Daylight Time (EDT; UTC-4 during DST periods or EST at UTC-5 when observing standard time) depending upon the season, but since we are given 9 PM in a generic "EST" which implies it might not be daylight saving adjusted yet. Assuming New York is currently using Standard Time: New York's current time (UTC): 9:00 pm + 5 hours = 2:00 AM UTC on March 15th Tokyo's current time (JST, UTC+9): Tokyo would then have the following local times: - If it were daylight saving adjusted in New York but not Japan: New York's current time (UTC) during DST: 9 PM + 4 hours = 1 AM on March 15th Tokyo's JST equivalent: 1 AM UTC + 9 hours = 10 AM on March 15th - If it were Standard Time in both: New York's current time (UTC): 2 AM as calculated above. Tokyo's JST equivalent would still be the same since Japan does not observe daylight saving times, so Tokyo remains at 11 PM on March 14th. Therefore, depending upon whether New York is observing Daylight Saving Time or Standard Time in this scenario and assuming it isn't DST adjusted (as EST implies), we can conclude that if it's currently 9 PM EST in NYC without considering the possibility of daylight saving time adjustments: - Tokyo would be at approximately 11:00 PM JST on March 14th. If New York is observing Daylight Saving Time, then Tokyo's current local time will still not change as Japan does not observe DST; thus it remains roughly around 10 AM JST in NYC’s case. Please note that the exact times can vary slightly due to differences between standard and daylight saving adjustments across different regions within a country.
One can control the output from a chat model to adhere a specific structured data format. To achieve this one would either use the dataclass or the Pydantic model.
The following code snippet creates a Pydantic data model that will conform to a specific data structure format:
from pydantic import BaseModel class GpuSpecs(BaseModel): name: str bus: str memory: int clock: int cores: int
The following code snippet instructs the chat model to conform the response to the specified structured schema and initiates a conversation by sending it some input:
structured_ollama_llm = ollama_chat_llm.with_structured_output(GpuSpecs)
result = structured_ollama_llm.invoke('Get all the GPU specs details for the AMD Radeon RX 7800')
print(f'Result type: {type(result)}, Result: {result}')
Executing the above Python code snippet generates the following typical output:
Result type: <class '__main__.GpuSpecs'>, Result: name='AMD Radeon RX 7800' bus='PCI Express x16' memory=256 clock=24000 cores=2
Even though the LLM model(s) have been trained on vast amounts of data, one needs to provide an appropriate context to the LLM model(s) for better response (or output). To get better results, one can augment the LLM model's knowledge by providing additional context from external data sources, such as vector stores. This is where the Retrieval Augmented Generation (or RAG for short) comes into play.
We will leverage the Chroma as the vector store for the RAG demo. In addition, we will handcraft as small dataset containing information on some popular leadership books.
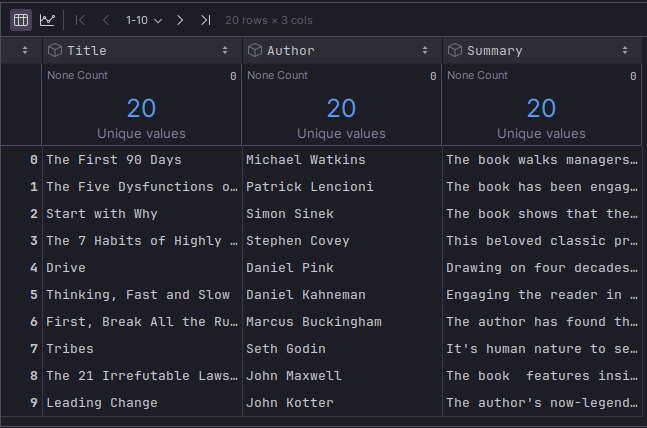
The following illustration depicts the truncated contents of the small leadership books dataset:
The pipe-separated leadership books dataset can be downloaded from HERE !!!
To load the pipe-separated leadership books dataset into a pandas dataframe, execute the following code snippet:
import pandas as pd books_df = pd.read_csv(books_dataset, sep='|') books_df
Executing the above Python code generates the typical output as shown in Figure.1 above.
The Document class allows one to encapsulate the textual content with metadata, which can be stored in a vector store for later searches.
To create a collection of documents from the rows of the pandas dataframe, execute the following code snippet:
from langchain_core.documents import Document
documents = []
for i in range(0, len(books_df)):
doc = Document(page_content=books_df.iloc[i]['Summary'], metadata={'Title': books_df.iloc[i]['Title'], 'Author': books_df.iloc[i]['Author']})
documents.append(doc)
documents
The following illustration depicts the partial collection of documents:
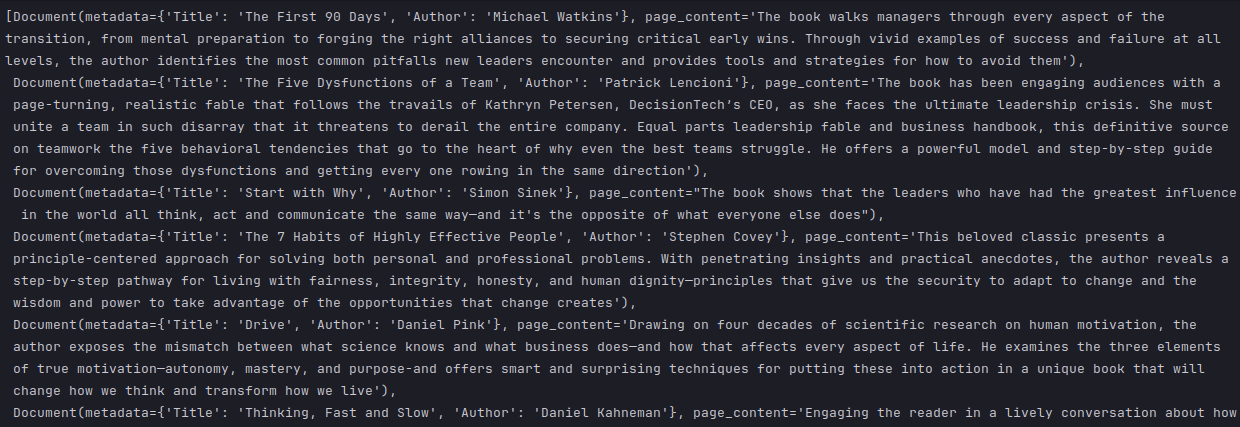
To store the documents (with textual content) into a vector store (as embeddings), we need to create an instance of vector embedding class corresponding to the LLM model. To create an instance of Ollama embedding, execute the following code snippet:
from langchain_core.embeddings.embeddings import Embeddings from langchain_ollama import OllamaEmbeddings ollama_embedding: Embeddings = OllamaEmbeddings(base_url=ollama_base_url, model=ollama_chat_model)
Executing the above Python code generates no output.
To create an instance of the Chroma vector store with Ollama embedding, execute the following code snippet:
from langchain_chroma import Chroma vector_store = Chroma(embedding_function=ollama_embedding, persist_directory=chroma_db_dir)
Executing the above Python code generates no output.
To persist the collection of documents into the Chroma vector store, execute the following code snippet:
vector_store.add_documents(documents)
The following illustration depicts the list of document IDs stored in the vector store:
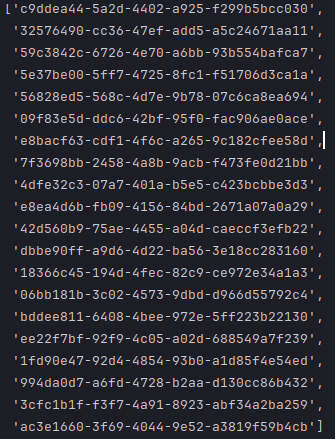
To create an instance of a vector store retriever that will return at most 2 similar documents, execute the following code snippet:
n_top = 2
retriever = vector_store.as_retriever(search_kwargs={'k': n_top})
Executing the above Python code generates no output.
To perform a query on similar documents from the Chroma vector store, execute the following code snippet:
query = 'guide to managing teams' similar_docs = retriever.invoke(query) similar_docs
The following illustration depicts the list of document IDs stored in the vector store:

To create a new prompt from a string template, with a placeholder for the contextual info from the vector store to instruct the LLM to generate a list of books by executing the following code snippet:
from langchain_core.prompts import ChatPromptTemplate
messages_template = ChatPromptTemplate.from_messages(
[
('system', 'You are a helpful assistant.'),
('human', 'Generate a numbered list of top three books on topic of {subject} that are similar to the following book: {title}')
]
)
messages = messages_template.format(subject='leadership', title=similar_docs[0].metadata['Title'])
Executing the above Python code generates no output.
To initiate a conversation that sends the new prompt to our LLM chat model, execute the following code snippet:
result = ollama_chat_llm.invoke(messages) result.pretty_print()
Executing the above Python code generates the following typical output:
================================== Ai Message ================================== 1. "Leadership Secrets of Attila the Hun" by John C. Maxwell - This classic work delves into ancient wisdom and timeless principles for becoming an effective leader, much like how 'Atomic Habits' explores habits as a key factor in achieving success. 2. "The 7 Habitudes: A New Vision on Leadership Development" by Peter M. Senge & Michael L. Roberts - The book offers insights about the seven essential qualities of successful leaders and provides practical advice for cultivating them, similar to how 'Atomic Habits' focuses on habits as a means towards achieving goals. 3. "The Five Dysfunctions of a Team: A Leadership Fable" by Patrick Lencioni - This insightful work explores common challenges faced in team settings that hinder effective leadership development; it offers valuable lessons and strategies for overcoming these obstacles, much like how 'Atomic Habits' provides practical advice on developing good habits to achieve success.
Moving on to the example on keeping a history of all the conversations so that the chat model remembers the context of the interactions.
To initialize an in-memory store that will preserve responses from the previous chat model interaction(s), execute the following code snippet:
messages = [ SystemMessage(content='You are a helpful assistant.'), HumanMessage(content='Suggest the most popular top 3 leadership quotes') ]
Executing the above Python code generates no output.
To initiate the first conversation with the chat model, execute the following code snippet:
result = ollama_chat_llm.invoke(messages, config=config) result.pretty_print()
Executing the above Python code generates the following typical output:
================================== Ai Message ================================== Certainly! Here are three highly regarded and inspirational leadership quotes: 1. "The greatest leader is not necessarily the one who does everything himself, but rather he is the one who knows which tasks to delegate." - Dwight D. Eisenhower 2. “Leadership is a journey of never stopping learning.” - Richard Branson (Sir Richard) 3. “A good decision is made by listening first and speaking last; it's not about being right all time - it's knowing when you're wrong, then changing course accordingly quickly enough to still get somewhere worthwhile in the end." - Simon Sinek These quotes encapsulate timeless wisdom on leadership that continues to inspire leaders across various fields.
To demonstrate that the chat model remembers and uses the previous chat response(s) as a context in the next interaction, execute the following code snippet:
messages.append(HumanMessage(content='Quotes too long and are not that inspiring. Can you try again?')) result = ollama_chat_llm.invoke(messages, config=config) result.pretty_print()
Executing the above Python code generates the following typical output:
================================== Ai Message ================================== Sure! Here's an attempt at shorter, more impactful versions of three famous leadership quotes: 1. "Leadership is getting others to do something which you're convinced they should be doing anyway." - John C. Maxwell 2. "The best way to predict the future is to create it yourself" - Peter Drucker. 3. “A leader's job is for him/her not so much to convince as simply to inspire.” - Warren Bennis. I hope these versions are more inspiring!
Next, we will move on to the topic of leveraging LangChain for building agents that can perform specific tasks using provided external tools.
The LangChain ReAct Framework is a technique that enables LangChain virtual agents to interact with LLMs through prompting, which mimics the reasoning (Re) and acting (Act) behavior of a human to solve problems in an environment, using various external tools. In other words, the ReAct framework enables LLMs to reason and act based on the observations.
To create an instance of a virtual agent that will interact with an underlying chat model, execute the following code snippet:
from langchain.agents import create_agent
ollama_tools_llm = init_chat_model('ollama:'+ollama_tools_model, base_url=ollama_base_url, temperature=llm_temperature)
agent = create_agent(ollama_tools_llm,
system_prompt='You are a helpful assistant.')
Executing the above Python code generates no output.
Note that the just created virtual agent has no access to any external tool(s).
To initiate an action by the virtual agent, execute the following code snippet:
question_1 = 'Can you all the network interfaces on this system?'
result = agent.invoke(
{'messages': [
{
'role': 'user',
'content': question_1
}
]}
)
result
Executing the above Python code generates the following typical output:
{'messages': [HumanMessage(content='Can you all the network interfaces on this system?', additional_kwargs={}, response_metadata={}, id='df81c6cf-61e6-4806-8978-c05c6d2188da'),
AIMessage(content='To list all the network interfaces on your system, you can use different commands depending on the operating system:\n\nFor Linux or Unix-based systems (like Ubuntu, Debian, CentOS):\n\n1. Open the terminal.\n2. Type `ip addr show` and press Enter.\n\nThis command will display a list of all available network interfaces along with their IP addresses and other details.\n\nFor Windows:\n\n1. Open Command Prompt.\n2. Type `get interface ip configuration` and press Enter.\n\nThis command will open the Network Connections window, where you can see a list of all your network adapters and their status.', additional_kwargs={}, response_metadata={'model': 'granite4:micro', 'created_at': '2025-11-09T15:28:13.602499284Z', 'done': True, 'done_reason': 'stop', 'total_duration': 3264429161, 'load_duration': 1966303355, 'prompt_eval_count': 29, 'prompt_eval_duration': 16360001, 'eval_count': 120, 'eval_duration': 1203746467, 'model_name': 'granite4:micro', 'model_provider': 'ollama'}, id='lc_run--b118b8a5-6f88-4ed1-90ec-aa3188362e76-0', usage_metadata={'input_tokens': 29, 'output_tokens': 120, 'total_tokens': 149})]}
From the Output.7 above, it is clear that the LLM model could only provide instructions versus actually performing the task !
In order to enable a virtual agent to actually perform some action, one needs to provide the agent with access to some external tool(s).
To create a custom tool for executing system commands, execute the following code snippet:
import subprocess
from langchain.tools import tool
@tool
def execute_shell_command(command: str) -> str:
"""Tool to execute shell commands
Arg:
command (str): Shell command to execute
Returns:
str: Output of the command execution
"""
print(f'Executing shell command: {command}')
try:
output = subprocess.run(command, shell=True, check=True, text=True, capture_output=True)
if output.returncode != 0:
return f'Error executing shell command - {command}'
return output.stdout
except subprocess.CalledProcessError as e:
print(e)
Executing the above Python code generates no output.
To create a virtual agent that will interact with an underlying chat model and has access to our custom tool, execute the following code snippet:
tools = [execute_shell_command]
prompt = '''
You are a helpful assistant. Be concise and accurate.
You have access to the following tools:
{tools}
Use these tools to answer the user's question.
Only respond with the output of the command execution.
'''
agent = create_agent(ollama_tools_llm,
tools,
system_prompt=prompt)
Executing the above Python code generates no output.
To initiate an action by the virtual agent, execute the following code snippet:
result = agent.invoke(
{'messages': [
{
'role': 'user',
'content': question_1
}
]}
)
result
Executing the above Python code generates the following typical output:
Executing shell command: ip addr show
{'messages': [HumanMessage(content='Can you all the network interfaces on this system?', additional_kwargs={}, response_metadata={}, id='34870440-d9b6-423e-a47c-6fedb96718ca'),
AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'granite4:micro', 'created_at': '2025-11-09T15:29:46.365442678Z', 'done': True, 'done_reason': 'stop', 'total_duration': 501183998, 'load_duration': 99492929, 'prompt_eval_count': 245, 'prompt_eval_duration': 66565128, 'eval_count': 30, 'eval_duration': 315432435, 'model_name': 'granite4:micro', 'model_provider': 'ollama'}, id='lc_run--89751081-ebd9-4a23-be0e-2bf49d233e05-0', tool_calls=[{'name': 'execute_shell_command', 'args': {'command': 'ip addr show'}, 'id': '3900ff6e-5d87-4761-8b9c-7f9d1d3abcc9', 'type': 'tool_call'}], usage_metadata={'input_tokens': 245, 'output_tokens': 30, 'total_tokens': 275}),
ToolMessage(content='1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000\n link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00\n inet 127.0.0.1/8 scope host lo\n valid_lft forever preferred_lft forever\n inet6 ::1/128 scope host noprefixroute \n valid_lft forever preferred_lft forever\n2: enp42s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000\n link/ether 04:04:16:17:04:04 brd ff:ff:ff:ff:ff:ff\n inet 192.168.1.25/24 brd 192.168.1.255 scope global noprefixroute enp42s0\n valid_lft forever preferred_lft forever\n inet6 fe80::a850:4daa:5d33:2919/64 scope link noprefixroute \n valid_lft forever preferred_lft forever\n3: wlo1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000\n link/ether 50:50:e8:ee:50:50 brd ff:ff:ff:ff:ff:ff\n altname wlp41s0\n4: br-b83cfae028ea: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default \n link/ether aa:aa:8d:a2:aa:aa brd ff:ff:ff:ff:ff:ff\n inet 172.19.0.1/16 brd 172.19.255.255 scope global br-b83cfae028ea\n valid_lft forever preferred_lft forever\n5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default \n link/ether de:de:ef:36:de:de brd ff:ff:ff:ff:ff:ff\n inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0\n valid_lft forever preferred_lft forever\n inet6 fe80::dcbf:ef80:fe36:cf80/64 scope link \n valid_lft forever preferred_lft forever\n8: veth5e858b9@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default \n link/ether 42:42:41:0e:42:42 brd ff:ff:ff:ff:ff:ff link-netnsid 0\n inet6 fe80::9c74:1cff:fe7d:e647/64 scope link \n valid_lft forever preferred_lft forever\n', name='execute_shell_command', id='6b3a35df-f4e1-40fe-8cf3-7258efe7d1ba', tool_call_id='3900ff6e-5d87-4761-8b9c-7f9d1d3abcc9'),
AIMessage(content='Here are the network interfaces on this system:\n\n1. **lo** (Loopback)\n - Description: Loopback interface for local communication.\n - IP Addresses:\n - IPv4: 127.0.0.1/8\n - IPv6: ::1/128\n\n2. **enp42s0**\n - Description: Ethernet interface, likely the primary network connection.\n - Details:\n - MTU: 1500 bytes\n - IP Address: 192.168.1.25/24 (configured via DHCP or static)\n - IPv6: fe80::a85e:4dca:5db3:2919/64\n\n3. **wlo1**\n - Description: Wireless interface, possibly a Wi-Fi connection.\n - Details:\n - Currently DOWN (no carrier signal).\n - MAC Address: 50:c2:e8:ee:d1:73\n - Alternative name: wlp41s0\n\n4. **br-b83cfae028ea**\n - Description: Bridge interface for network segmentation or virtualization.\n - Details:\n - MTU: 1500 bytes\n - IP Address: 172.19.0.1/16 (configured via DHCP or static)\n - MAC Address: aa:9c:8d:a2:7f:63\n\n5. **docker0**\n - Description: Docker bridge interface for container networking.\n - Details:\n - MTU: 1500 bytes\n - IP Address: 172.17.0.1/16 (configured via DHCP or static)\n - IPv6: fe80::dcbf:efff:fe36:cf61/64\n\n6. **veth5e858b@if2**\n - Description: Virtual Ethernet interface pair used for container networking.\n - Details:\n - MTU: 1500 bytes\n - IP Address: fe80::9c74:1cff:fe7d:e647/64 (configured via link-local addressing)\n - Associated with Docker bridge `docker0`\n\nThese interfaces provide a comprehensive overview of the network setup on this system, including local loopback, primary Ethernet/Wi-Fi connections, virtualization bridges, and container networking.', additional_kwargs={}, response_metadata={'model': 'granite4:micro', 'created_at': '2025-11-09T15:29:52.099690935Z', 'done': True, 'done_reason': 'stop', 'total_duration': 5723652410, 'load_duration': 95177663, 'prompt_eval_count': 978, 'prompt_eval_duration': 235624822, 'eval_count': 475, 'eval_duration': 5116439823, 'model_name': 'granite4:micro', 'model_provider': 'ollama'}, id='lc_run--4b0b3342-74ec-4236-a545-b84002715e49-0', usage_metadata={'input_tokens': 978, 'output_tokens': 475, 'total_tokens': 1453})]}
To extract the actual response from the tool execution, execute the following code snippet:
from langchain_core.messages import ToolMessage tool_messages = [msg for msg in result['messages'] if isinstance(msg, ToolMessage)] if tool_messages: print(tool_messages[-1].content)
Executing the above Python code generates the following typical output:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp42s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 04:04:04:17:04:04 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.25/24 brd 192.168.1.255 scope global noprefixroute enp42s0
valid_lft forever preferred_lft forever
inet6 fe80::a880:4d80:5db3:2980/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: wlo1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 50:50:50:ee:d1:50 brd ff:ff:ff:ff:ff:ff
altname wlp41s0
4: br-b83cfae028ea: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether aa:aa:aa:a2:7f:aa brd ff:ff:ff:ff:ff:ff
inet 172.19.0.1/16 brd 172.19.255.255 scope global br-b83cfae028ea
valid_lft forever preferred_lft forever
5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether de:de:de:36:cf:de brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::dcbf:efff:fe36:cf61/64 scope link
valid_lft forever preferred_lft forever
8: veth5e858b9@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 42:42:42:0e:7b:42 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::9c74:1cff:fe7d:e647/64 scope link
valid_lft forever preferred_lft forever
For the next demonstration, we will levarage the Auto MPG dataset saved as a SQLite database, which can be downloaded from HERE !!!
To create an instance of the SQLite database using the provided dataset, execute the following code snippet:
from langchain_community.utilities import SQLDatabase mpg_db = SQLDatabase.from_uri(mpg_sqlite_url)
Executing the above Python code generates no output.
To create a custom tool for executing SQL queries, execute the following code snippet:
from dataclasses import dataclass
from langgraph.runtime import get_runtime
from langchain.tools import tool
@dataclass
class RuntimeDbContext:
db: SQLDatabase
@tool
def execute_sql(query: str) -> str:
"""
Execute SQL query and return results.
Arg:
query (str): SQL query to execute
Returns:
Query results as a string
"""
runtime = get_runtime(RuntimeDbContext)
db = runtime.context.db
try:
return db.run(query)
except Exception as e:
return f'Error: {str(e)}'
Executing the above Python code generates no output.
Note that an instance of the data class RuntimeDbContext allows the virtual agent to access the database when using the external tool.
To create a virtual agent that will interact with an underlying chat model and has access to our custom tool (along with the underlying SQLite database), execute the following code snippet:
db_prompt = ''' You are a helpful SQLite assistant. You are able to answer questions about the Auto MPG database. Rules: - Think step-by-step - When you need data, call the tool execute_sql with ONLY one SQL query as input - DO NOT use INSERT, UPDATE, DELETE, or DROP statements - Limit up to 5 rows of output - If the tool returns an 'Error:', revise the SQL query and try again ''' agent = create_agent( ollama_tools_llm, tools=[execute_sql], system_prompt=db_prompt, context_schema=RuntimeDbContext, checkpointer=InMemorySaver() )
Executing the above Python code generates no output.
To initiate an action by the virtual agent, execute the following code snippet:
question_1 = 'what are the names of all the tables and their columns in the Auto MPG database?'
# This is very *IMPORTANT* as it associates a unique id for the conversational thread
config = {'configurable': {'thread_id': 'thr-1'}}
for step in agent.stream(
{'messages': question_1},
context=RuntimeDbContext(db=mpg_db),
config=config,
stream_mode='values',
):
step['messages'][-1].pretty_print()
Notice that we are passing an instance of RuntimeDbContext as a runtime context to the agent. A runtime context provides static configuration, such as, user id, db connection, or other dependencies to the agent during its execution.
Executing the above Python code generates the following typical output:
================================ Human Message =================================
what are the names of all the tables and their columns in the Auto MPG database?
================================== Ai Message ==================================
Tool Calls:
execute_sql (dd945d57-e52d-4d1e-b9c8-6d8cb369834d)
Call ID: dd945d57-e52d-4d1e-b9c8-6d8cb369834d
Args:
query: SELECT name FROM sqlite_master WHERE type='table';
================================= Tool Message =================================
Name: execute_sql
[('Origins',), ('Vehicles',)]
================================== Ai Message ==================================
Tool Calls:
execute_sql (1c4d7c82-1398-494c-b1d1-de26aa4c3852)
Call ID: 1c4d7c82-1398-494c-b1d1-de26aa4c3852
Args:
query: PRAGMA table_info(Origins);
================================= Tool Message =================================
Name: execute_sql
[(0, 'origin_id', 'BIGINT', 0, None, 1), (1, 'origin', 'TEXT', 0, None, 0)]
================================== Ai Message ==================================
Tool Calls:
execute_sql (b46fb5d3-8c67-4fa4-9fab-41b72ba3a85d)
Call ID: b46fb5d3-8c67-4fa4-9fab-41b72ba3a85d
Args:
query: PRAGMA table_info(Vehicles);
================================= Tool Message =================================
Name: execute_sql
[(0, 'vehicle_id', 'BIGINT', 0, None, 1), (1, 'mpg', 'FLOAT', 0, None, 0), (2, 'cylinders', 'BIGINT', 0, None, 0), (3, 'displacement', 'FLOAT', 0, None, 0), (4, 'horsepower', 'FLOAT', 0, None, 0), (5, 'weight', 'FLOAT', 0, None, 0), (6, 'acceleration', 'FLOAT', 0, None, 0), (7, 'model_year', 'BIGINT', 0, None, 0), (8, 'origin', 'BIGINT', 0, None, 0), (9, 'car_name', 'TEXT', 0, None, 0)]
================================== Ai Message ==================================
The Auto MPG database contains two tables:
**1. Origins**
- Columns:
- `origin_id` (INTEGER)
- `origin` (TEXT)
**2. Vehicles**
- Columns:
- `vehicle_id` (INTEGER)
- `mpg` (REAL)
- `cylinders` (INTEGER)
- `displacement` (REAL)
- `horsepower` (REAL)
- `weight` (REAL)
- `acceleration` (REAL)
- `model_year` (INTEGER)
- `origin` (INTEGER)
- `car_name` (TEXT)
To continue the workflow of the virtual agent, execute the following code snippet:
question_2 = 'what is the name of the car, the origin name, and the model year for the lowest mpg vehicle in the Auto MPG database?'
for step in agent.stream(
{'messages': question_2},
context=RuntimeDbContext(db=mpg_db),
config=config,
stream_mode='values',
):
step['messages'][-1].pretty_print()
Executing the above Python code generates the following typical output:
================================ Human Message =================================
what is the name of the car, the origin name, and the model year for the lowest mpg vehicle in the Auto MPG database?
================================== Ai Message ==================================
Tool Calls:
execute_sql (1f3376c5-7a1f-438d-a507-9c6c98913947)
Call ID: 1f3376c5-7a1f-438d-a507-9c6c98913947
Args:
query: SELECT v.car_name, o.origin FROM Vehicles v JOIN Origins o ON v.origin = o.origin_id ORDER BY v.mpg ASC LIMIT 1
================================= Tool Message =================================
Name: execute_sql
[('hi 1200d', 'USA')]
================================== Ai Message ==================================
The vehicle with the lowest miles per gallon (MPG) in the Auto MPG database is **"hi 1200d"**, originating from **USA**, and was manufactured in the year **70**.
Finally, we will cover the topic on controlling the behavior of virtual agents using the Middleware component in LangChain.
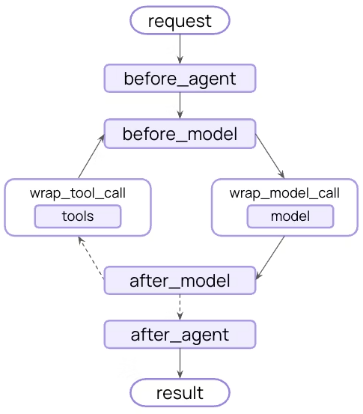
A Middleware essentially exposes method hooks, which are called at various points of a virtual agent interaction, such as, before the agent call, before the model call, after the model call, after the agent call, etc.
LangChain out of the box provides few Middleware implementations as follows:
The following illustration depicts the various interception points in a agent interaction:
For the next demonstration, we will make use of the SummarizationMiddleware along with a custom logging Middleware !!!
To create a custom logging Middleware that will intercept before and after a model call, execute the following code snippet:
from langchain.agents.middleware import AgentMiddleware, AgentState,
from langgraph.runtime import Runtime
from typing import Any
class LoggingMiddleware(AgentMiddleware):
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f'LoggingMiddleware:: Before - Messages Count: {len(state["messages"])}')
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f'LoggingMiddleware:: After - Messages Count: {len(state["messages"])}')
return None
Executing the above Python code generates no output.
To create an instance of the LoggingMiddleware and the SummarizationMiddleware that will only keep the last 3 conversational messages, execute the following code snippet:
from langchain.agents.middleware import SummarizationMiddleware
middleware = SummarizationMiddleware(
model=llm_provider+ollama_chat_model,
messages_to_keep=3,
summary_prompt='Summarize earlier context concisely.'
)
custom_middleware = LoggingMiddleware()
Executing the above Python code generates no output.
To create a virtual agent that will use the two Middlewares and interact with an underlying chat model, execute the following code snippet:
config = {'configurable': {'thread_id': 'agent-1'}}
memory = InMemorySaver()
agent = create_agent(ollama_tools_llm,
system_prompt='You are a helpful assistant who addresses me by my name when you respond.',
middleware=[custom_middleware, middleware],
checkpointer=memory)
Executing the above Python code generates no output.
To interact with the virtual agent through a series of questions, execute the following code snippet:
questions = [
'Hey, my name is Vader. Would like to ask you few history questions',
'What is the capital of France?',
'What is the total population of France?',
'What is the currency of Japan?',
'What is the capital of Germany?'
'What is the total population of Germany?',
'What is the currency of Spain?',
'What is the capital of Italy?',
'What is the total population of Italy?'
]
for question in questions:
print(f'--- Question: {question}')
result = agent.invoke({
'messages': [{
'role': 'user',
'content': question
}]
},
config=config)
print(f'--- Answer: {result["messages"][-1].content}')
Executing the above Python code generates the following typical output:
--- Question: Hey, my name is Vader. Would like to ask you few history questions LoggingMiddleware:: Before - Messages Count: 1 LoggingMiddleware:: After - Messages Count: 2 --- Answer: Of course, Vader! I'd be happy to help with your history questions. Please feel free to ask anything you're curious about. --- Question: What is the capital of France? LoggingMiddleware:: Before - Messages Count: 3 LoggingMiddleware:: After - Messages Count: 4 --- Answer: The capital of France is Paris, Vader. It's a city known for its historical landmarks and cultural institutions such as the Eiffel Tower, Louvre Museum, and Notre-Dame Cathedral. --- Question: What is the total population of France? LoggingMiddleware:: Before - Messages Count: 5 LoggingMiddleware:: After - Messages Count: 5 --- Answer: As of my last update, the estimated population of France was around 67 million people, Vader. Please note that this number can vary slightly depending on the source and the exact date of the estimate. --- Question: What is the currency of Japan? LoggingMiddleware:: Before - Messages Count: 6 LoggingMiddleware:: After - Messages Count: 5 --- Answer: The currency of Japan, my dear friend, is the Japanese Yen (JPY). --- Question: What is the capital of Germany?What is the total population of Germany? LoggingMiddleware:: Before - Messages Count: 6 LoggingMiddleware:: After - Messages Count: 5 --- Answer: The capital city of Germany, John, is Berlin. As for its total population, it's quite hard to provide an exact number as it keeps changing over time due to births, deaths and migration. However, according to the latest data from 2021, the estimated population of Germany was around 83 million people. --- Question: What is the currency of Spain? LoggingMiddleware:: Before - Messages Count: 6 LoggingMiddleware:: After - Messages Count: 5 --- Answer: The official currency of Spain, John, is the Euro (€). It's represented by the symbol EUR and is used in many countries across Europe including Spain itself. --- Question: What is the capital of Italy? LoggingMiddleware:: Before - Messages Count: 6 LoggingMiddleware:: After - Messages Count: 5 --- Answer: The capital city of Italy, John, is Rome. It's a beautiful place with rich history and culture. --- Question: What is the total population of Italy? LoggingMiddleware:: Before - Messages Count: 6 LoggingMiddleware:: After - Messages Count: 5 --- Answer: As of my last update, the estimated population of Italy was around 60 million people, John. However, please note that this number can vary as it depends on when and where you look for the most recent data.
From the Output.12 above, notice that the agent only keeps upto 5 messages and has lost the context of the name Vader after some interactions.
With this, we conclude the hands-on demonstration of using the various LangChain components !!!
References