Figure.1
| PolarSPARC |
Quick Primer on Open WebUI with Ollama
| Bhaskar S | *UPDATED*05/31/2025 |
Overview
Open WebUI is a popular, open source, user friendly, and web-based UI platform that allows one to locally host and interact with various LLM models using OpenAI compatible LLM runners, such as Ollama.
In this primer, we will demonstrate how one can effectively setup and run the Open WebUI along with the Ollama platform using pre-built Docker images.
Installation and Setup
The installation and setup will can on a Ubuntu 24.04 LTS based Linux desktop AND a Apple Silicon based Macbook Pro. Ensure that Docker is installed and setup on the desktop (see instructions).
For Linux and MacOS, ensure that Ollama platform is installed and setup on the desktop (see instructions).
For Linux and MacOS, we will setup two required directories by executing the following command in a terminal window:
$ mkdir -p $HOME/.ollama/open-webui
For Linux and MacOS, to pull and download the docker image for open-webui, execute the following command in a terminal window:
$ docker pull ghcr.io/open-webui/open-webui:0.6.13
The following should be the typical output:
0.6.13: Pulling from open-webui/open-webui 61320b01ae5e: Pull complete fa70febde0f6: Pull complete 9d545c45fb8c: Pull complete 09c4893e5320: Pull complete 331425d04a0a: Pull complete 4f4fb700ef54: Pull complete e59efb0a4f10: Pull complete cf1f8292132e: Pull complete 5fe20a65e325: Pull complete dc36d13e3503: Pull complete 83e9df231c27: Pull complete 3c537f9569f7: Pull complete f1b7f5f04ad1: Pull complete cc1f0481efaa: Pull complete 7f3cf9d660ec: Pull complete Digest: sha256:ddc64d14ec933e8c1caf017df8a0068bece3e35acbc59e4aa4971e5aa4176a72 Status: Downloaded newer image for ghcr.io/open-webui/open-webui:0.6.13 ghcr.io/open-webui/open-webui:0.6.13
This completes all the system installation and setup for the Open WebUI hands-on demonstration.
Hands-on with Open WebUI
In the following sections, we will show the commands for both Linux and MacOS, however, we will ONLY show the output from Linux. Note that all the commands have been tested on both Linux and MacOS respectively.
Assuming that the ip address on the Linux desktop is 192.168.1.25, start the Ollama platform by executing the following command in the terminal window:
$ docker run --rm --name ollama --network=host -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.9.0
For MacOS, start the Ollama platform by executing the following command in the terminal window:
$ docker run --rm --name ollama --network=host -p 11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.9.0
The following should be the typical output:
time=2025-05-31T00:42:59.447Z level=INFO source=routes.go:1234 msg="server config" env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:4096 OLLAMA_DEBUG:INFO OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]" time=2025-05-31T00:42:59.450Z level=INFO source=images.go:479 msg="total blobs: 23" time=2025-05-31T00:42:59.451Z level=INFO source=images.go:486 msg="total unused blobs removed: 0" time=2025-05-31T00:42:59.451Z level=INFO source=routes.go:1287 msg="Listening on [::]:11434 (version 0.9.0)" time=2025-05-31T00:42:59.451Z level=INFO source=gpu.go:217 msg="looking for compatible GPUs" time=2025-05-31T00:42:59.453Z level=INFO source=gpu.go:377 msg="no compatible GPUs were discovered" time=2025-05-31T00:42:59.453Z level=INFO source=types.go:130 msg="inference compute" id=0 library=cpu variant="" compute="" driver=0.0 name="" total="62.7 GiB" available="57.6 GiB"
For the hands-on demonstration, we will use the Microsoft Phi-4 Mini pre-trained LLM model.
For Linux and MacOS, open a new terminal window and execute the following docker command to download the desired LLM model:
$ docker exec -it ollama ollama run phi4-mini
After the pre-trained LLM model is downloaded successfully, the command would wait for an user input.
To test the just downloaded LLM model, execute the following user prompt:
>>> describe a gpu in less than 50 words in json format
The following should be the typical output on Linux:
```json
{
"gpu": {
"description": "A Graphics Processing Unit optimized for rendering images and videos, accelerating computational tasks."
}
}
```
To exit the user input, execute the following user prompt:
>>> /bye
Now we will shift gears to get our hands dirty with Open WebUI.
On Linux, to start the Open WebUI platform, execute the following command in a new terminal window:
$ docker run --rm --name open-webui --network=host --add-host=host.docker.internal:host-gateway -p 192.168.1.25:8080:8080 -v $HOME/.ollama/open-webui:/app/backend/data -e WEBUI_AUTH=False -e OLLAMA_API_BASE_URL=http://192.168.1.25:11434/api ghcr.io/open-webui/open-webui:0.6.13
On MacOS, to start the Open WebUI platform, execute the following command in a new terminal window:
$ docker run --rm --name open-webui --network=host --add-host=host.docker.internal:host-gateway -p 8080:8080 -v $HOME/.ollama/open-webui:/app/backend/data -e WEBUI_AUTH=False -e OLLAMA_API_BASE_URL=http://127.0.0.1:11434/api ghcr.io/open-webui/open-webui:0.6.13
The following should be the typical trimmed output:
-Loading WEBUI_SECRET_KEY from file, not provided as an environment variable.
Generating WEBUI_SECRET_KEY
Loading WEBUI_SECRET_KEY from .webui_secret_key
...[ TRIM ]...
WARNING: CORS_ALLOW_ORIGIN IS SET TO '*' - NOT RECOMMENDED FOR PRODUCTION DEPLOYMENTS.
INFO [open_webui.env] Embedding model set: sentence-transformers/all-MiniLM-L6-v2
WARNI [langchain_community.utils.user_agent] USER_AGENT environment variable not set, consider setting it to identify your requests.
...[ TRIM ]...
INFO: Started server process [1]
INFO: Waiting for application startup.
2025-05-31 22:04:38.110 | INFO | open_webui.utils.logger:start_logger:140 - GLOBAL_LOG_LEVEL: INFO - {}
2025-05-31 22:04:38.111 | INFO | open_webui.main:lifespan:489 - Installing external dependencies of functions and tools... - {}
2025-05-31 22:04:38.118 | INFO | open_webui.utils.plugin:install_frontmatter_requirements:241 - No requirements found in frontmatter. - {}
On Linux and MacOS, the docker command options --network=host AND --add-host=host.docker.internal:host-gateway are very IMPORTANT as it enables a container to connect to services on the host
On Linux, open the web browser and enter the URL link http://192.168.1.25:8080 and on MacOS, open the web browser and enter the URL link http://127.0.0.1:8080.
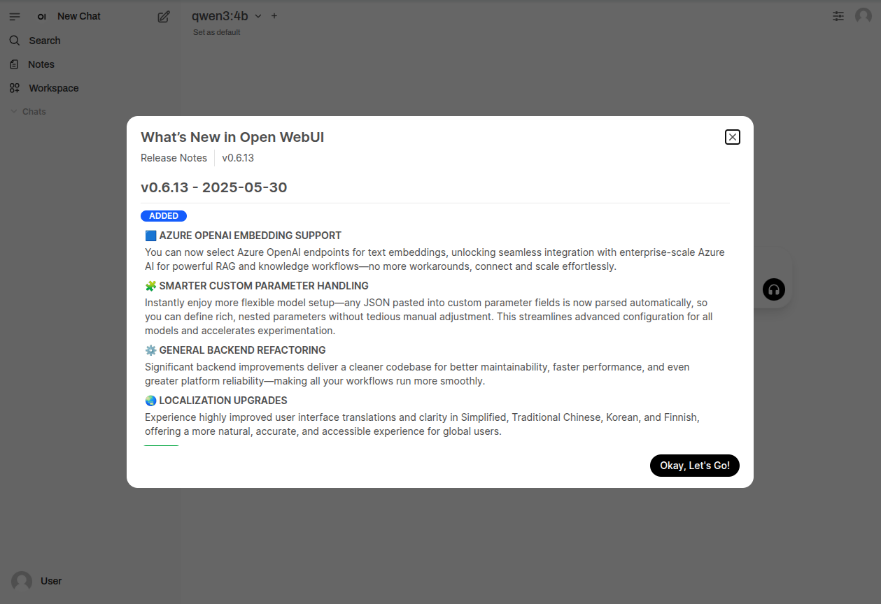
The following illustration depicts the browser presented to the user on launch on Linux:
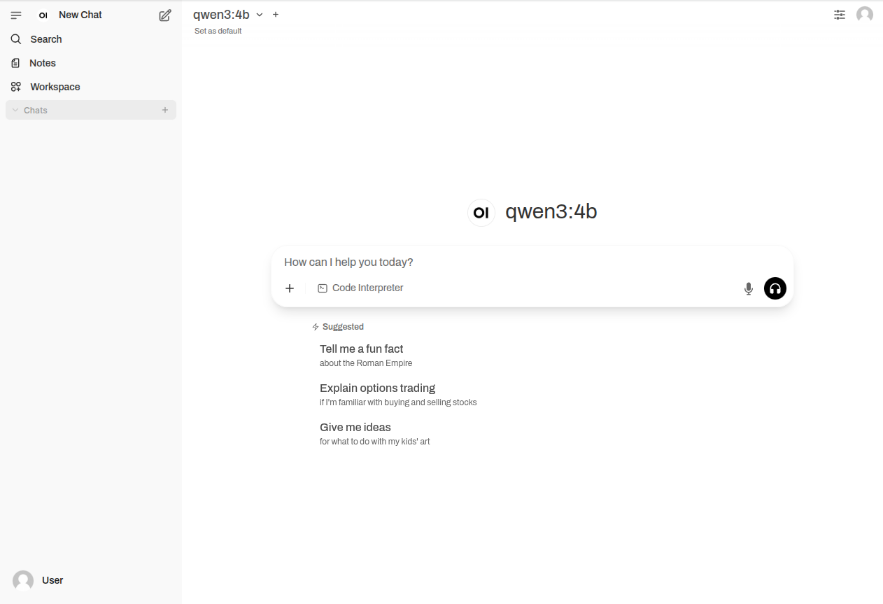
Click on the Okay, Let's Go! button to navigate to the main screen as shown in the following illustration:
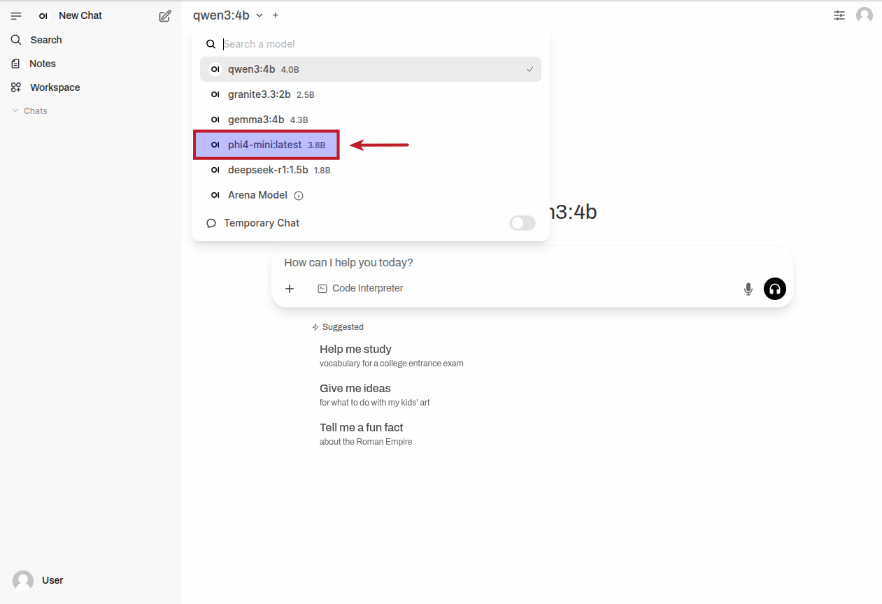
Click on the top left qwen3:4b drop-down to select the phi4-mini:latest model as shown in the following illustration:
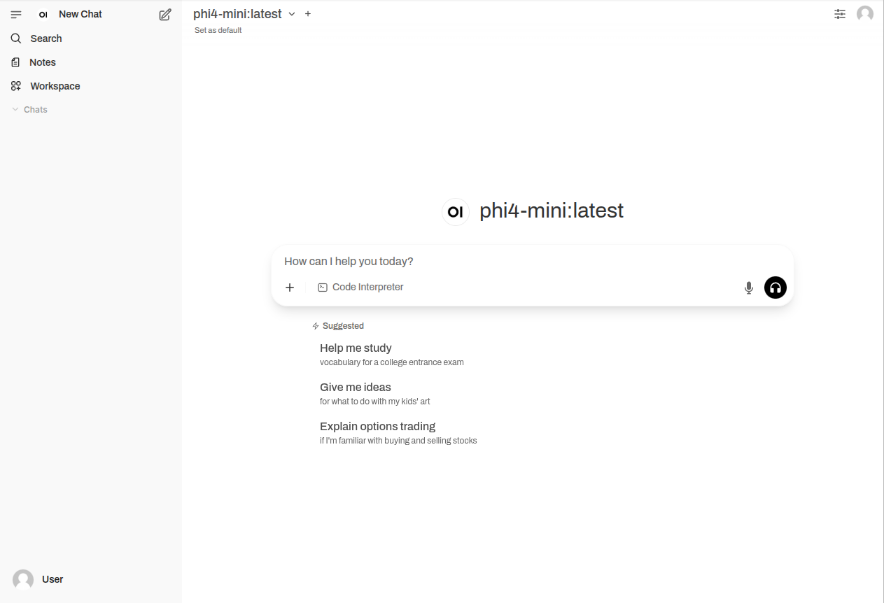
Once the phi4-mini:latest LLM model is selected, one is presented with a screen as shown in the following illustration:
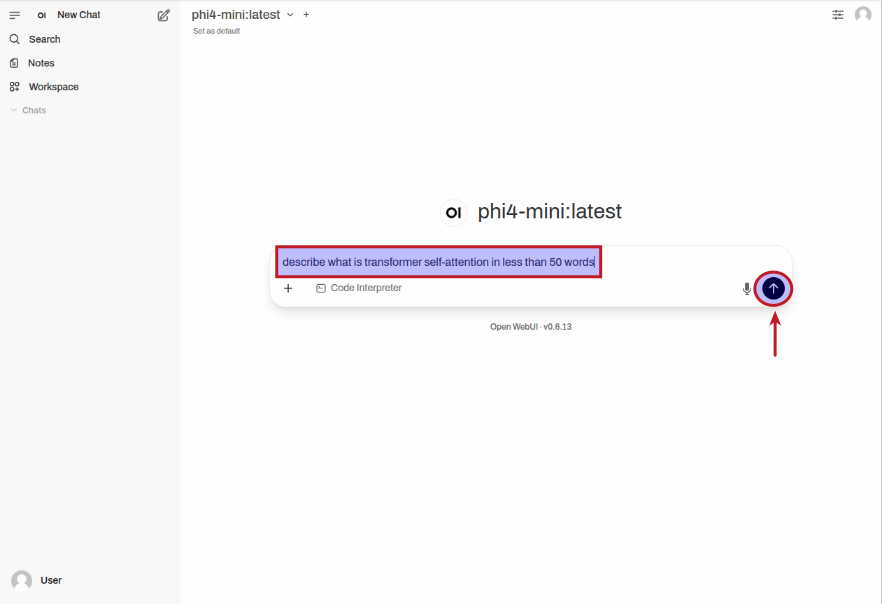
Next step is to enter a user prompt in the prompt textbox and click on the Up Arrow as shown in the following illustration:
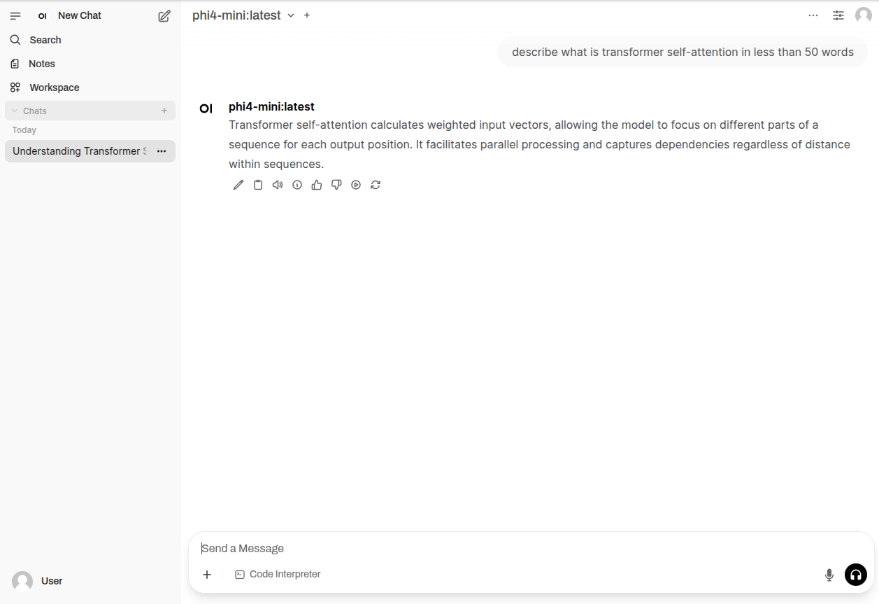
The LLM model will respond with a text corresponding to the user prompt as shown in the following illustration:
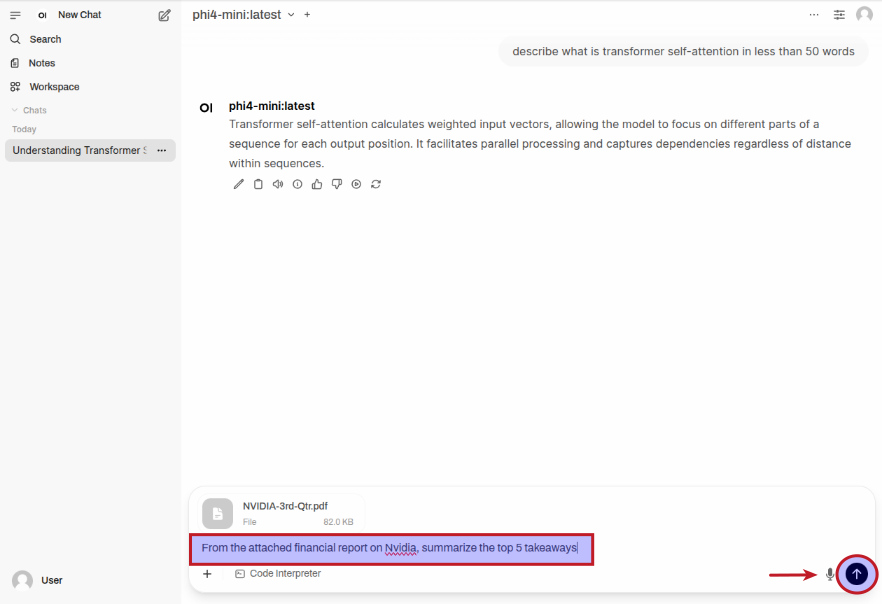
For the next task, we will use the Nvidia 3rd Quarter 2024 financial report to analyze it !!!
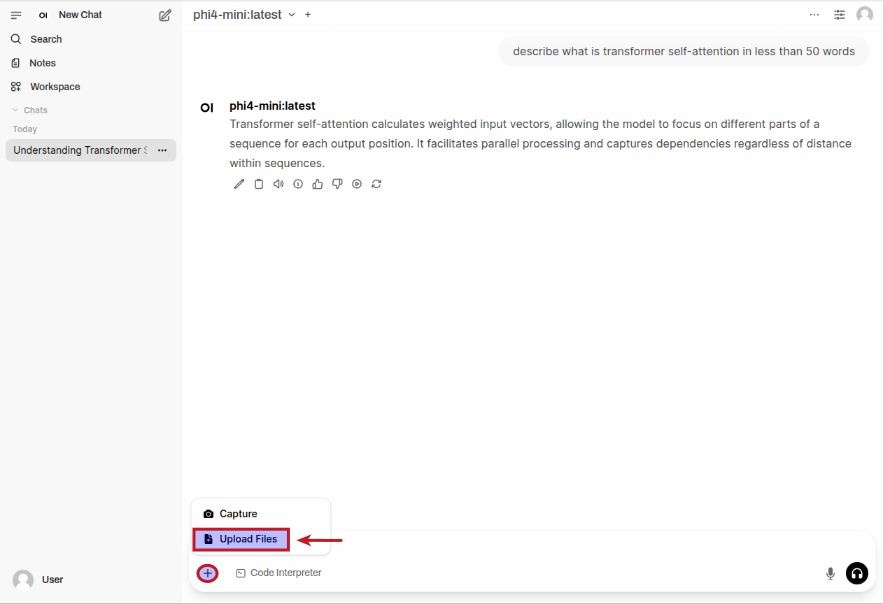
First we need to upload the financial report PDF by first clicking on the + and then the Upload Files option as shown in the following illustration:
Once the document has been uploaded, enter a user prompt in the prompt textbox and then click on the Up Arrow as shown in the following illustration:
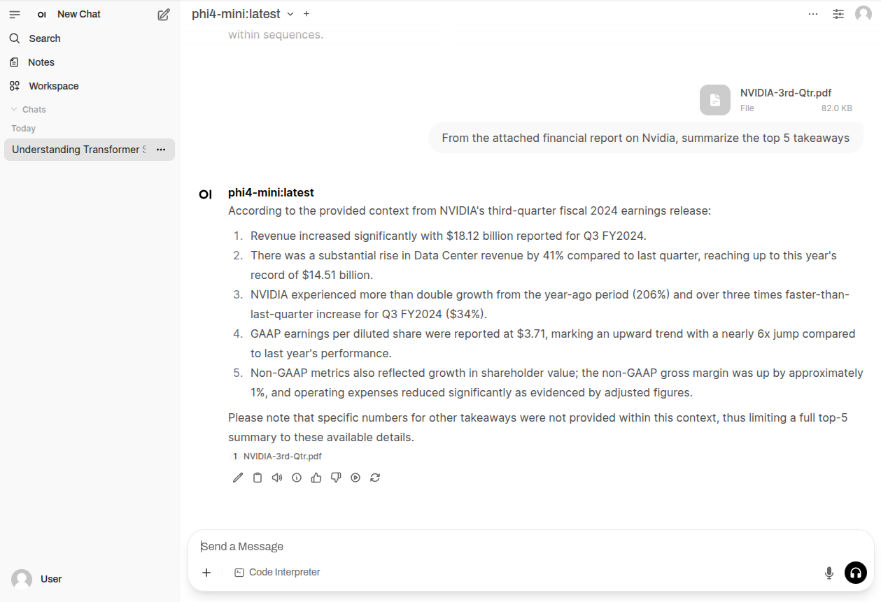
The LLM model will respond with the following response as shown in the following illustration:
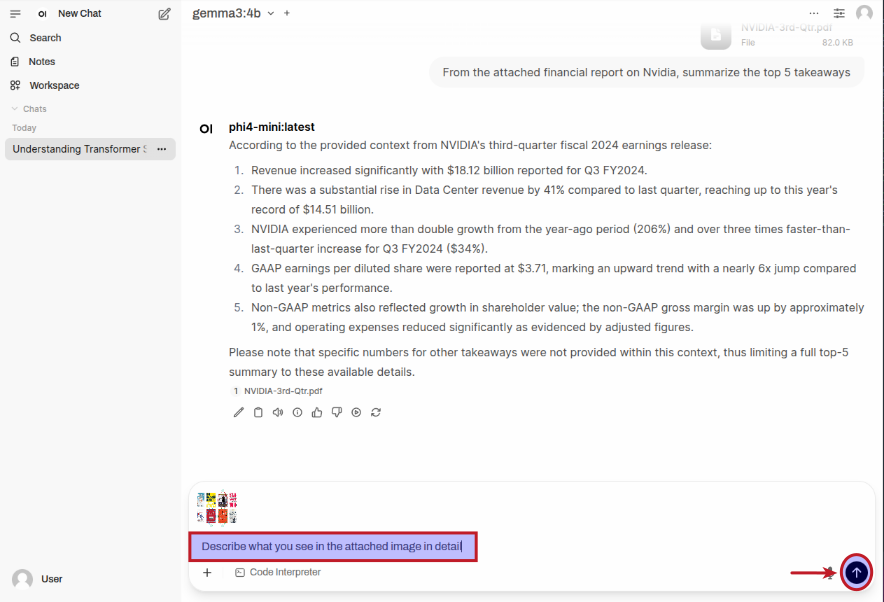
Now, for the next task, we will use this image of Leadership Books to analyze and describe it !!!
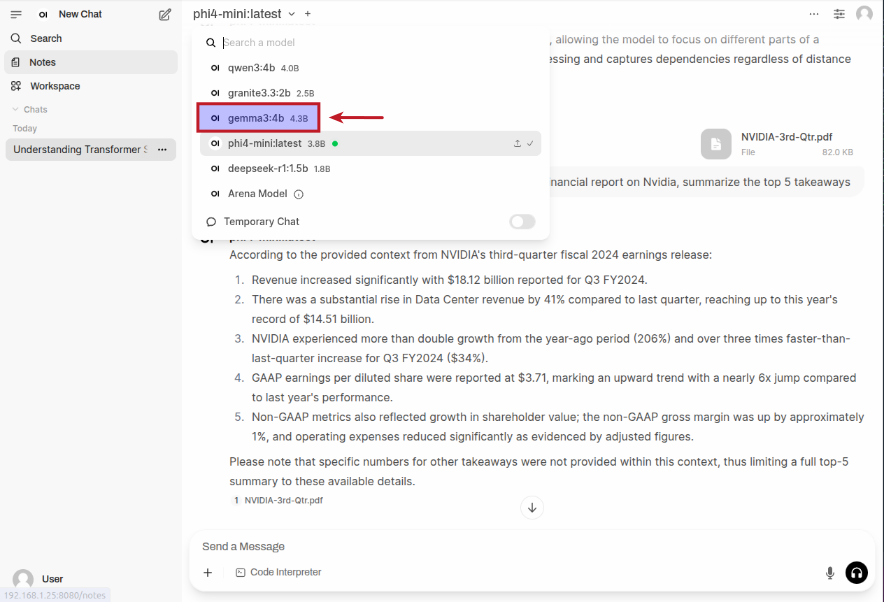
Click on the top left phi4-mini:latest drop-down to select the gemma3:4b model as shown in the following illustration:
Once the gemma3:4b LLM model is selected, upload the desired image, enter a user prompt in the prompt textbox and then click on the Up Arrow as shown in the following illustration:
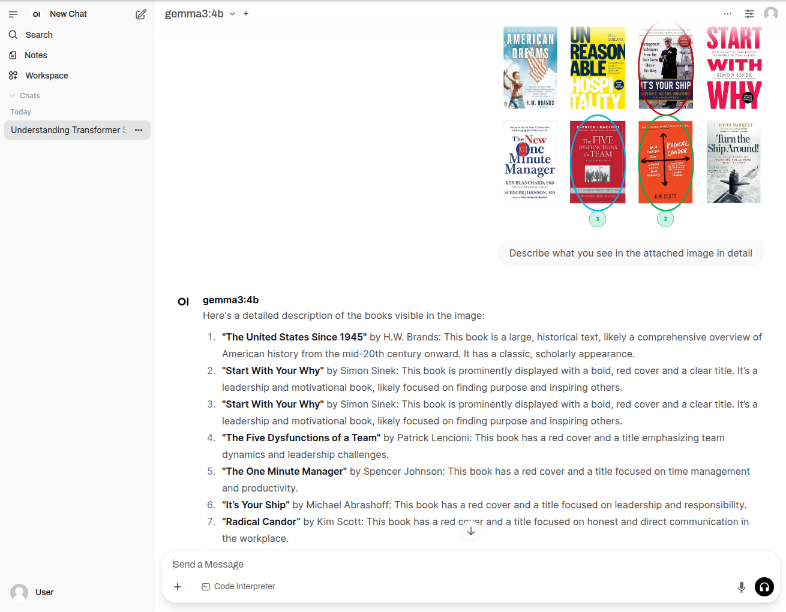
The LLM model will respond with the following response as shown in the following illustration:
Moving along to the next task, one again click on the top left gemma3:4b drop-down to select the qwen3:4b model as shown in the following illustration:
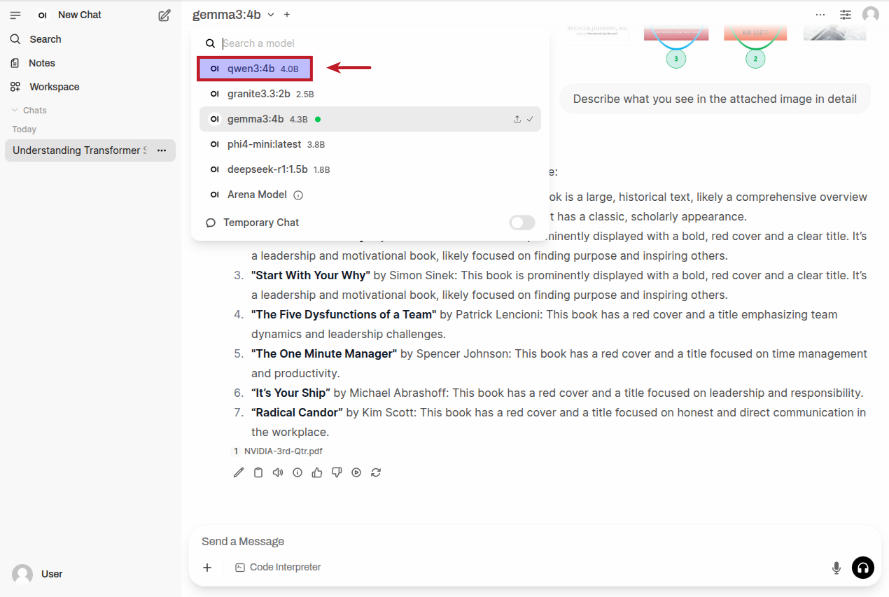
Once the qwen3:4b LLM model is selected, enter a user prompt in the prompt textbox and then click on the Up Arrow as shown in the following illustration:
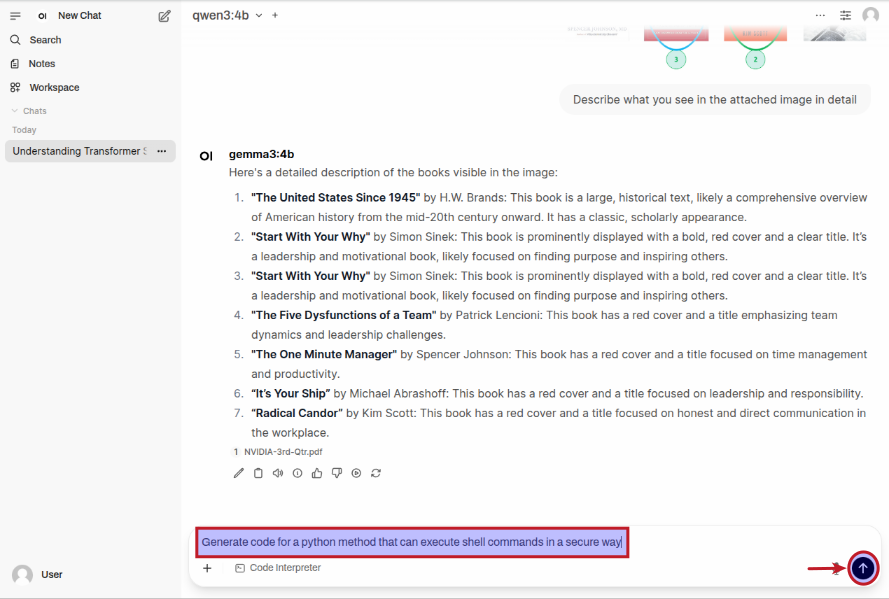
The LLM model will respond with the following response as shown in the following illustration:
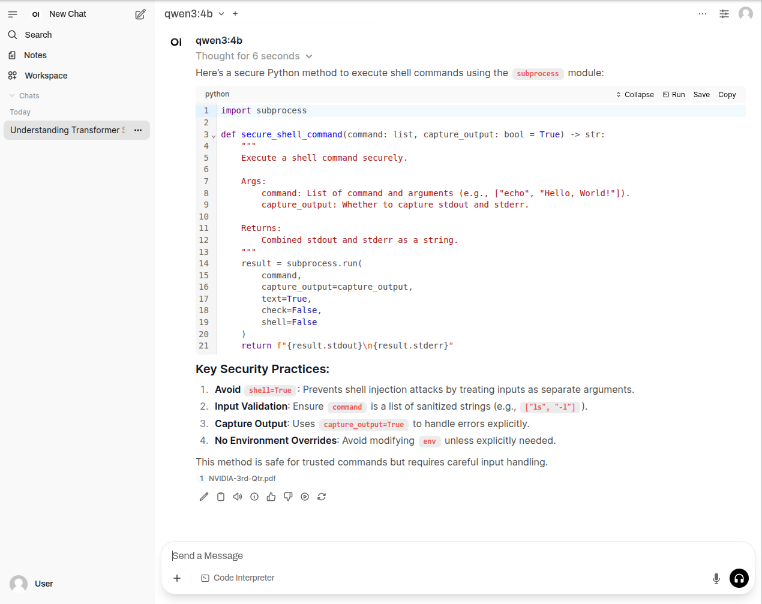
BINGO - we have successfully tested Open WebUI interfacing with Ollama !
References