| PolarSPARC |
Quick Bytes - PgVector Vector Store
| Bhaskar S | 05/16/2025 |
Overview
Embedding is the process of transforming a piece of data (audio, image, text, etc) into a numerical vector representation in a multi-dimensional vector space that maintains the semantic meaning of the data, which can then be used to find similar pieces of data in that vector space, since vectors of similar pieces of data tend to be close to each other in that vector space.
A Vector Store is a special type of data store that is designed for efficient storage and retrieval of data represented as embedding vectors. One can then query the vector store to find similar vectors using the nearest neighbor search algorithm.
Note that the data must first be converted to an embedding vector using an embedding model (an LLM model), before it can be stored in OR queried from a vector store.
In this short article, we will demonstrate the use of PgVector (PostgreSQL with Vector) as the vector store.
Installation and Setup
The installation and setup will be on a Ubuntu 24.04 LTS based Linux desktop. Ensure that Docker is installed and setup on the desktop (see instructions).
Also, ensure that the Python 3.1x programming language is installed.
To install the desired Python modules for this short primer, execute the following command:
$ pip install csv dotenv openai psycopg_binary
To pull and download the docker image for pgvector, execute the following command in a terminal window:
$ docker pull pgvector/pgvector:pg17
The following should be the typical output:
pg17: Pulling from pgvector/pgvector 7cf63256a31a: Pull complete 543c6dea2e39: Pull complete dc87fb4dbc03: Pull complete 55c54708c8e7: Pull complete 878a40f56a67: Pull complete 6424ae1ae883: Pull complete 600e770d797e: Pull complete a21a08dbca2c: Pull complete 783086ffbe8e: Pull complete 42e76ffa3e07: Pull complete fcccafd45a4d: Pull complete 420a047e4570: Pull complete 553d1749e29f: Pull complete bc13f9b1d80d: Pull complete 3b97b7cee64f: Pull complete 4f106352a559: Pull complete Digest: sha256:5982c00a2cdf786c2daefa45ad90277309c6f8f5784a4332acc34963c2d61ba3 Status: Downloaded newer image for pgvector/pgvector:pg17 docker.io/pgvector/pgvector:pg17
Finally, ensure that the Ollama platform is installed and setup on the desktop (see instructions).
Assuming that the ip address on the Linux desktop is 192.168.1.25, start the Ollama platform by executing the following command in the terminal window:
$ docker run --rm --name ollama --network=host -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.6.7
If the linux desktop has Nvidia GPU with decent amount of VRAM (at least 16 GB) and has been enabled for use with docker (see instructions), then execute the following command instead to start Ollama:
$ docker run --rm --name ollama --gpus=all --network=host -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama ollama/ollama:0.6.7
For the LLM model, we will be using the recently released IBM Granite 3.3 2B model.
Open a new terminal window and execute the following docker command to download the LLM model:
$ docker exec -it ollama ollama run granite3.3:2b
To start the PgVector server, execute the following command in the terminal window:
$ docker run --rm --name pgvector -e POSTGRES_DB=ps_vector -e POSTGRES_USER=pgusr -e POSTGRES_PASSWORD=pgusr\$123 -p 5432:5432 -v /tmp/pgvector:/var/lib/postgresql/data pgvector/pgvector:pg17
The following should be the typical trimmed output:
.....[ TRIM ]..... PostgreSQL init process complete; ready for start up. 2025-05-11 19:37:22.098 UTC [1] LOG: starting PostgreSQL 17.4 (Debian 17.4-1.pgdg120+2) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit 2025-05-11 19:37:22.098 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432 2025-05-11 19:37:22.098 UTC [1] LOG: listening on IPv6 address "::", port 5432 2025-05-11 19:37:22.101 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432" 2025-05-11 19:37:22.107 UTC [65] LOG: database system was shut down at 2025-05-11 19:37:22 UTC 2025-05-11 19:37:22.112 UTC [1] LOG: database system is ready to accept connections
This completes all the installation and setup for the PgVector hands-on demonstrations in Python.
Hands-on with PgVector
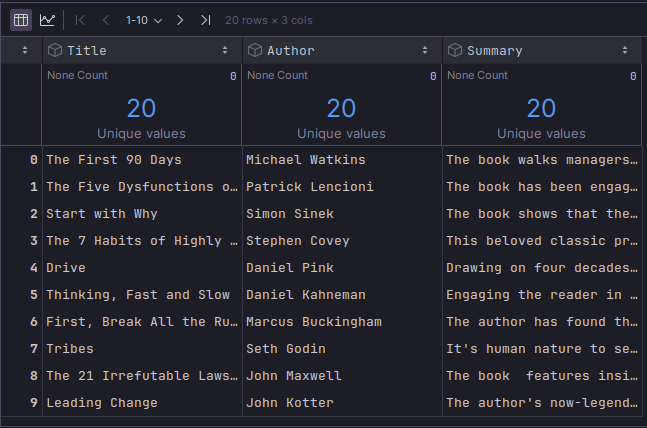
For the hands-on demo, we will make use of the following small, handcrafted textual dataset containing information on some popular leadership books.
The following illustration depicts the truncated contents of the small leadership books dataset:
This small, handcrafted, pipe-separated leadership books dataset can be downloaded from the PolarSPARC website located HERE !!!
Create a file called .env with the following environment variables defined:
OLLAMA_MODEL='granite3.3:2b' OLLAMA_BASE_URL='http://192.168.1.25:11434/v1' OLLAMA_API_KEY='ollama' PG_VECTOR_DB=postgres://pgusr:pgusr$123@192.168.1.25:5432/ps_vector DOCS_DATASET='./data/leadership_books.csv'
One of the most important task when working with any vector store is to convert data into an embedding vector. One can use the LLM model to convert the data into an embedding vector. The following Python class abstracts the embedding task:
class EmbeddingClient:
def __init__(self):
_api_key = os.getenv('OLLAMA_API_KEY')
_base_url = os.getenv('OLLAMA_BASE_URL')
self._model = os.getenv('OLLAMA_MODEL')
logger.info(f'Base URL: {_base_url}, Ollama Model: {self._model}')
self._client = OpenAI(api_key=_api_key, base_url=_base_url)
def get_embedding(self, text: str) -> list[float]:
logger.info(f'Text length: {len(text)}, text (trimmed): {text[:20]}')
try:
response = self._client.embeddings.create(input=text, model=self._model)
return response.data[0].embedding
except Exception as e:
logger.error(f'Error occurred while getting embedding: {e}')
return None
In the __init__() method, we initialize an instance of the OpenAI class for the Ollama running on the host URL. Note the api_key is just a dummy value.
In the get_embedding(text) method, we use the OpenAI instance to get the embedding vector for the specified text.
The following Python class abstracts the interactions with the PgVector:
class PgVectorEmbedding:
def __init__(self):
_pg_vector_db = os.getenv('PG_VECTOR_DB')
logger.info(f'Vector db: {_pg_vector_db}')
try:
self.vector_db = psycopg.connect(_pg_vector_db)
except Exception as e:
logger.error(f'Error occurred while connecting to vector db: {e}')
# Enable Vector Extension
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
CREATE EXTENSION IF NOT EXISTS vector;
"""
)
# Create Vector Table
# Note - granite 3.3 creates a 2048 dimension embedding vector by default
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS docs_vector (
doc_id TEXT PRIMARY KEY,
doc_source TEXT,
doc_content TEXT,
doc_embedding VECTOR(2048)
);
"""
)
logger.info('Vector table setup and created successfully!')
def add_embedding(self, doc_id: str, doc_source: str, doc_content: str, doc_embedding: list[float]):
logger.info(f'Doc id: {doc_id}, Doc source: {doc_source}, Doc embedding (trimmed): {doc_embedding[:20]}...')
if doc_embedding is not None:
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
INSERT INTO docs_vector (doc_id, doc_source, doc_content, doc_embedding)
VALUES (%s, %s, %s, %s);
""",
(doc_id, doc_source, doc_content, str(doc_embedding)))
self.vector_db.commit()
def query_embedding(self, query: str, embedding: list[float]):
logger.info(f'Query: {query}')
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
SELECT
doc_id, doc_source, doc_content
FROM docs_vector
ORDER BY doc_embedding <-> %s LIMIT 3;
""",
(str(embedding),))
results = cursor.fetchall()
return results
def cleanup(self):
# Delete Vector Table
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
DROP TABLE IF EXISTS docs_vector;
"""
)
self.vector_db.commit()
self.vector_db.close()
In the __init__() method, we first connect to the PgVector database, then enable the vector extension, and finally create the docs_vector database table with an embedding column of size 2048. This is crucial since it is the default size of the embedding vector from the LLM model IBM Granite 3.3.
In the add_embedding(doc_source, doc_content, doc_embedding) method, we store the passed in data elements (including the embedding vector) in to the vector store.
In the query_embedding(embedding) method, we query the vector store using the user specified embedding to find similar data rows (documents).
The following Python code brings all the pieces together to demonstrate the use of PgVector:
#
# @Author: Bhaskar S
# @Blog: https://polarsparc.github.io
# @Date: 11 May 2025
#
#
# Prerequisites:
#
# docker run --rm --name ollama --gpus=all --network=host -p 192.168.1.25:11434:11434 -v $HOME/.ollama:/root/.ollama
# ollama/ollama:0.6.7
#
# docker run --rm --name pgvector -e POSTGRES_DB=ps_vector -e POSTGRES_USER=pgusr -e POSTGRES_PASSWORD=pgusr\$123
# -p 5432:5432 -v /tmp/pgvector:/var/lib/postgresql/data pgvector/pgvector:pg17
#
import csv
import logging
import os
import psycopg
from dotenv import load_dotenv, find_dotenv
from openai import OpenAI
# Global Variables
load_dotenv(find_dotenv())
# Logging Configuration
logging.basicConfig(format='%(asctime)s | %(levelname)s -> %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=logging.INFO)
# Logger
logger = logging.getLogger('PgVectorDemo')
class EmbeddingClient:
def __init__(self):
_api_key = os.getenv('OLLAMA_API_KEY')
_base_url = os.getenv('OLLAMA_BASE_URL')
self._model = os.getenv('OLLAMA_MODEL')
logger.info(f'Base URL: {_base_url}, Ollama Model: {self._model}')
self._client = OpenAI(api_key=_api_key, base_url=_base_url)
def get_embedding(self, text: str) -> list[float]:
logger.info(f'Text length: {len(text)}, text (trimmed): {text[:20]}')
try:
response = self._client.embeddings.create(input=text, model=self._model)
return response.data[0].embedding
except Exception as e:
logger.error(f'Error occurred while getting embedding: {e}')
return None
class PgVectorEmbedding:
def __init__(self):
_pg_vector_db = os.getenv('PG_VECTOR_DB')
logger.info(f'Vector db: {_pg_vector_db}')
try:
self.vector_db = psycopg.connect(_pg_vector_db)
except Exception as e:
logger.error(f'Error occurred while connecting to vector db: {e}')
# Enable Vector Extension
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
CREATE EXTENSION IF NOT EXISTS vector;
"""
)
# Create Vector Table
# Note - granite 3.3 creates a 2048 dimension embedding vector by default
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS docs_vector (
doc_id TEXT PRIMARY KEY,
doc_source TEXT,
doc_content TEXT,
doc_embedding VECTOR(2048)
);
"""
)
logger.info('Vector table setup and created successfully!')
def add_embedding(self, doc_id: str, doc_source: str, doc_content: str, doc_embedding: list[float]):
logger.info(f'Doc id: {doc_id}, Doc source: {doc_source}, Doc embedding (trimmed): {doc_embedding[:20]}...')
if doc_embedding is not None:
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
INSERT INTO docs_vector (doc_id, doc_source, doc_content, doc_embedding)
VALUES (%s, %s, %s, %s);
""",
(doc_id, doc_source, doc_content, str(doc_embedding)))
self.vector_db.commit()
def query_embedding(self, query: str, embedding: list[float]):
logger.info(f'Query: {query}')
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
SELECT
doc_id, doc_source, doc_content
FROM docs_vector
ORDER BY doc_embedding <-> %s LIMIT 3;
""",
(str(embedding),))
results = cursor.fetchall()
return results
def cleanup(self):
# Delete Vector Table
with self.vector_db.cursor() as cursor:
cursor.execute(
"""
DROP TABLE IF EXISTS docs_vector;
"""
)
self.vector_db.commit()
self.vector_db.close()
def main():
docs_dataset = os.getenv('DOCS_DATASET')
logger.info(f'Docs dataset: {docs_dataset}')
embedding_client = EmbeddingClient()
pg_vector_embedding = PgVectorEmbedding()
# Add each line from the CSV file to the vector table
skip_first_row = True
doc_id = 11
with open(docs_dataset) as csv_file:
csv_reader = csv.reader(csv_file, delimiter='|')
for row in csv_reader:
if skip_first_row:
skip_first_row = False
else:
doc_title = row[0]
doc_author = row[1]
doc_summary = row[2]
logger.info(f'Doc title: {doc_title}, Doc author: {doc_author}, Doc summary (trimmed): {doc_summary[:20]}...')
doc_embedding = embedding_client.get_embedding(doc_summary)
logger.info(f'Document - id: {doc_id}, embedding: {doc_embedding}')
if doc_embedding is not None:
# Note - it is important to call serialize_float32
pg_vector_embedding.add_embedding(str(doc_id), doc_title, doc_summary, doc_embedding)
doc_id += 1
# Query time
query = 'How should one transform oneself?'
logger.info(f'Query: {query}')
embedding = embedding_client.get_embedding(query)
logger.info(f'Query embedding (trimmed): {embedding[:20]}...')
if embedding is not None:
results = pg_vector_embedding.query_embedding(query, embedding)
for result in results:
logger.info(f'Doc id: {result[0]}, Doc source: {result[1]}, Doc content (trimmed): {result[2][:20]}...')
# Cleanup
pg_vector_embedding.cleanup()
if __name__ == '__main__':
main()
Executing the above Python code would generate the following typical trimmed output:
2025-05-11 20:39:27 | INFO -> Docs dataset: ./data/leadership_books.csv 2025-05-11 20:39:27 | INFO -> Base URL: http://192.168.1.25:11434/v1, Ollama Model: granite3.3:2b 2025-05-11 20:39:27 | INFO -> Vector db: postgres://pgusr:pgusr$123@192.168.1.25:5432/ps_vector 2025-05-11 20:39:27 | INFO -> Vector table setup and created successfully! 2025-05-11 20:39:27 | INFO -> Doc title: The First 90 Days, Doc author: Michael Watkins, Doc summary (trimmed): The book walks manag... 2025-05-11 20:39:27 | INFO -> Text length: 337, text (trimmed): The book walks manag 2025-05-11 20:39:28 | INFO -> HTTP Request: POST http://192.168.1.25:11434/v1/embeddings "HTTP/1.1 200 OK" 2025-05-11 20:39:28 | INFO -> Document - id: 11, embedding: [-0.0068606343, -0.01972573, -0.023916194, -0.0010518635, -0.015610875]... 2025-05-11 20:39:28 | INFO -> Doc id: 11, Doc source: The First 90 Days, Doc embedding (trimmed): [-0.0068606343, -0.01972573, -0.023916194, -0.0010518635, -0.015610875, 0.011689153, 0.0003136391, 0.025542324, -0.009759403, 0.024362244, 0.015517925, -0.0043118005, 0.004119524, 0.011988029, -0.0040824623, 0.0024149762, -0.007935951, -0.010882921, 0.0041267592, 0.0028242848]... 2025-05-11 20:39:28 | INFO -> Doc title: The Five Dysfunctions of a Team, Doc author: Patrick Lencioni, Doc summary (trimmed): The book has been en... 2025-05-11 20:39:28 | INFO -> Text length: 583, text (trimmed): The book has been en 2025-05-11 20:39:28 | INFO -> HTTP Request: POST http://192.168.1.25:11434/v1/embeddings "HTTP/1.1 200 OK" 2025-05-11 20:39:28 | INFO -> Document - id: 12, embedding: [-0.016283434, -0.03716055, -0.011846734, -0.0012580696, -0.027688906]... 2025-05-11 20:39:28 | INFO -> Doc id: 12, Doc source: The Five Dysfunctions of a Team, Doc embedding (trimmed): [-0.016283434, -0.03716055, -0.011846734, -0.0012580696, -0.027688906, 0.01329071, 0.017982572, 0.0069051543, -0.002077275, 0.042566814, 0.0027110714, 0.0143034, 0.024088819, 0.013864863, -0.008866621, 0.0033054352, -0.009089917, -0.011840139, 0.0027512487, 0.00018054784]... 2025-05-11 20:39:28 | INFO -> Doc title: Start with Why, Doc author: Simon Sinek, Doc summary (trimmed): The book shows that ... 2025-05-11 20:39:28 | INFO -> Text length: 173, text (trimmed): The book shows that 2025-05-11 20:39:28 | INFO -> HTTP Request: POST http://192.168.1.25:11434/v1/embeddings "HTTP/1.1 200 OK" 2025-05-11 20:39:28 | INFO -> Document - id: 13, embedding: [-0.0005668871, -0.01471604, -0.028375702, 0.00024137179, -0.00739445]... 2025-05-11 20:39:28 | INFO -> Doc id: 13, Doc source: Start with Why, Doc embedding (trimmed): [-0.0005668871, -0.01471604, -0.028375702, 0.00024137179, -0.00739445, -0.000536519, 0.016916472, 0.02252936, 0.006903177, 0.010936606, -0.017402247, -0.012205898, 0.0032192068, 0.025146864, -0.01760926, 0.01118916, -0.027755221, -0.01665958, 0.0018159834, 0.012303036]... 2025-05-11 20:39:28 | INFO -> Doc title: The 7 Habits of Highly Effective People, Doc author: Stephen Covey, Doc summary (trimmed): This beloved classic... 2025-05-11 20:39:28 | INFO -> Text length: 409, text (trimmed): This beloved classic 2025-05-11 20:39:29 | INFO -> HTTP Request: POST http://192.168.1.25:11434/v1/embeddings "HTTP/1.1 200 OK" 2025-05-11 20:39:29 | INFO -> Document - id: 14, embedding: [0.0006308571, -0.015410067, -0.016599795, 0.01734247, -0.018478082]... [... TRIM ...] 2025-05-11 20:39:29 | INFO -> Doc id: 28, Doc source: Mindset, Doc embedding (trimmed): [-0.024336385, -0.021259407, -0.010284345, 0.01681757, -0.016982323, 0.019110715, 0.0010887425, 0.022238772, -0.013728457, 0.0125993155, 0.0022744925, 0.008238009, 0.05308583, 0.00792392, -0.004086147, -0.014635101, -0.0045999386, -0.018514475, 0.0021897708, -0.0201128]... 2025-05-11 20:39:29 | INFO -> Doc title: What Got You Here Won't Get You There, Doc author: Marshall Goldsmith, Doc summary (trimmed): Your hard work is pa... 2025-05-11 20:39:29 | INFO -> Text length: 548, text (trimmed): Your hard work is pa 2025-05-11 20:39:29 | INFO -> HTTP Request: POST http://192.168.1.25:11434/v1/embeddings "HTTP/1.1 200 OK" 2025-05-11 20:39:29 | INFO -> Document - id: 29, embedding: [-0.02166045, -0.023827193, -0.012616294, 0.0073131975, -0.008234249]... 2025-05-11 20:39:29 | INFO -> Doc id: 29, Doc source: What Got You Here Won't Get You There, Doc embedding (trimmed): [-0.02166045, -0.023827193, -0.012616294, 0.0073131975, -0.008234249, 0.010190819, 0.014773423, 0.0065620714, -0.0061996323, 0.016300293, 0.02250393, 0.004150456, 0.018679328, 0.009167817, -0.0049460996, -0.009475679, -0.002061774, -0.010786087, -0.012995087, -0.0016223069]... 2025-05-11 20:39:29 | INFO -> Doc title: Never Split the Difference, Doc author: Chris Voss, Doc summary (trimmed): The book takes you i... 2025-05-11 20:39:29 | INFO -> Text length: 697, text (trimmed): The book takes you i 2025-05-11 20:39:29 | INFO -> HTTP Request: POST http://192.168.1.25:11434/v1/embeddings "HTTP/1.1 200 OK" 2025-05-11 20:39:29 | INFO -> Document - id: 30, embedding: [-0.01166664, -0.026443895, 0.0022901595, 0.019888481, -0.016428934]... 2025-05-11 20:39:29 | INFO -> Doc id: 30, Doc source: Never Split the Difference, Doc embedding (trimmed): [-0.01166664, -0.026443895, 0.0022901595, 0.019888481, -0.016428934, -0.0037869932, 0.013388167, 0.027863704, -0.0049146083, 0.0001916911, 0.0119440025, 0.0033646657, 0.0045561455, -0.008165221, -0.012048417, -0.009840382, 0.0054842946, -0.012218429, 0.0028511942, -0.006059509]... 2025-05-11 20:39:29 | INFO -> Query: How should one transform oneself? 2025-05-11 20:39:29 | INFO -> Text length: 33, text (trimmed): How should one trans 2025-05-11 20:39:29 | INFO -> HTTP Request: POST http://192.168.1.25:11434/v1/embeddings "HTTP/1.1 200 OK" 2025-05-11 20:39:29 | INFO -> Query embedding (trimmed): [0.006456322, 0.0054998808, -0.0073192967, 0.025129363, -0.008538065, -0.0057370476, -0.020242915, 0.028748669, 0.0046074195, 0.017888336, -0.013312791, -0.0053964276, 0.01072178, 0.024055563, 0.0029090866, 0.00013527779, -0.010240677, -0.0060129086, 0.008501645, 0.005943845]... 2025-05-11 20:39:29 | INFO -> Query: How should one transform oneself? 2025-05-11 20:39:29 | INFO -> Doc id: 25, Doc source: Who Moved My Cheese, Doc content (trimmed): Exploring a simple w... 2025-05-11 20:39:29 | INFO -> Doc id: 14, Doc source: The 7 Habits of Highly Effective People, Doc content (trimmed): This beloved classic... 2025-05-11 20:39:29 | INFO -> Doc id: 15, Doc source: Drive, Doc content (trimmed): Drawing on four deca...
This concludes the hands-on demonstration on using the PgVector vector store !!!
References